概述:依靠TensorFlow2.4.1,实现了uims验证码的识别,准确率在97%-98%之间。
很久没有更新博客啦,uims的验证码很早之前就有去识别的想法,但是一直没有去学习机器学习、深度学习等方面的相关知识,最近才刚开始看吴恩达的机器学习,闲着没事一天天采集样本,然后今天搞代码,这次终于成功啦!!!
样本的采集:一开始在假期手动标注过2-3k个样本,不得不感叹自己实在是太勤快(憨憨)了,后来想到有现成的图片acr的接口(假期为了实时推送成绩用过),于是利用百度的api对样本进行采集和标注。因为代码不多,所以直接贴了(代码是根据群友的自动获取成绩魔改的,所以有些乱七八糟,不过能用就行hhhh)。
'''
Author : IceSpite
Date : 2021-03-30 18:58:39
LastEditTime : 2021-04-03 20:33:18
'''
import json
import logging
import random
import os
import time
from hashlib import md5
from logging import *
from urllib import parse
import hashlib
import requests
import requests
import base64
username =
password =
baseURL = "https://uims.jlu.edu.cn/"
baseURL_VPN = "https://vpns.jlu.edu.cn/https/77726476706e69737468656265737421e5fe4c8f693a6445300d8db9d6562d/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded'
}
jsonHeaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
'Content-Type': 'application/json'
}
maxPredict = 5
delayTime = 5 * 60
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic" # 普通版 5000次
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic" # 精确版 500次
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/numbers"
def get_access_token():
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id= &client_secret= '
response = requests.get(host)
return response.json()['access_token']
def getCaptchaCode(img):
global request_url
img = base64.b64encode(img)
params = {"image": img}
access_token = get_access_token()
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
try:
if response.json()['error_code'] != "":
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
error("切换api版本")
except:
debug("api运行正常")
try:
res = response.json()['words_result'][0]['words']
except:
res = 1111
return res
def login(username, password, times):
global s, VPNUsername, VPNPassword
s = requests.session()
if times >= 10:
error("重试次数过多!可能是代码或网络出现问题,退出!")
time.sleep(5)
s.headers.update(headers)
try:
a = s.get("{}ntms/open/get-captcha-image.do?s={}".format(baseURL, random.randint(1, 65535)),
timeout=2).content
except:
login(username, password, times + 1)
return
else:
captchaCode = getCaptchaCode(a)
debug("识别验证码:"+captchaCode)
passwordMD5 = md5(
('UIMS' + username + password).encode('utf-8')).hexdigest()
loginData = {
'username': username,
'password': passwordMD5,
'mousePath': "",
'vcode': str(captchaCode)
}
loginData = parse.urlencode(loginData).encode('utf-8')
res = s.post(url="{}ntms/j_spring_security_check".format(baseURL),
data=loginData).content.decode()
# print(res)
if '登录错误' in res:
error("登录错误,重试!")
path = os.path.dirname(__file__) + '/errimgs/' + str(
captchaCode)+"_" + hashlib.md5(a).hexdigest() + ".jpg"
with open(path, 'wb') as f:
# # 保存
f.write(a)
login(username, password, times + 1)
else:
path = os.path.dirname(__file__) + '/uimsimgs/' + str(
captchaCode)+"_" + hashlib.md5(a).hexdigest() + ".jpg"
with open(path, 'wb') as f:
# # 保存
f.write(a)
warning("登录成功!")
return
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(levelname)s %(message)s')
warning('开始。')
s = requests.session()
for i in range(1000):
try:
login(username, password, 0)
except:
time.sleep(10)
然后CV工程师上线,在获取了8k左右的样本后几秒内即可训练完毕,利用保存的模型搭建了一个api,地址:http://icespite.top/api/uimscode,支持https访问,因为本站没有多少访问量,所以不设置访问次数。
请求格式:POST
| 参数 | 类型 |
| img | 文件 |
样例代码:
import requests
def getUimscode(img):
url = "http://icespite.top/api/uimscode"
files = {"img": img}
result = requests.post(url=url, files=files)
print(result.json())
return result.json()['value']
image = open(
"/home/icespite/Work/PycharmProjects/TensorFlow/errimgs/≌262_6761cdda81b2fdf8c9b0a75dd2e9020f.jpg", 'rb').read()
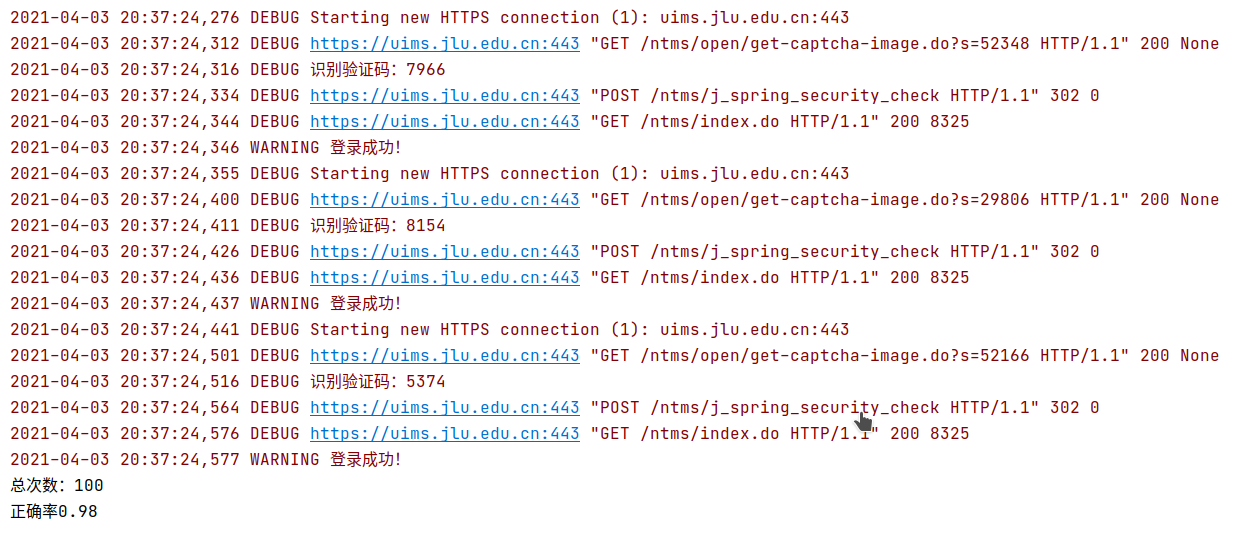
getUimscode(image)最后贴一下实际测试的正确率:

测试代码魔改一下最上面的就可以,相信聪明的你一定知道怎么搞得。
再贴一下1w个样本,点击下载
4月6日补充一个油猴脚本:吉林大学UIMS验证码自动填充
4月7日补充:借助之前的成果,快速补充样本集,目前已能够达到100次测试下的100%的正确率:

4月8日,收到院长警告了,不再搞样本了。限制接口访问量了,贴一下样本:百度网盘,提取码:l40o

谢谢,O(∩_∩)O,嘿嘿嘿
郭东伟: 就你 DDOS 我是吧?
笑死,直接被逮捕